Algoritma Best First Search
Best first search adalah algoritma yang mengeksplorasi sebuah grafik dengan cara memperluas node atau simpul yang paling menjanjikan yang dipilih sesuai dengan aturan yang ditentukan. Simpul merupakan gambaran dari area pencarian. Adapun grafik yang digunakan dalam best first search disebut grafik OR karena setiap cabangnya merepresentasikan jalan alternatif untuk penyelesaian masalah. Best first search bisa dibilang juga seperti mengembangkan simpul dari simpul sebelumnya. Simpul yang dikembangkan adalah simpul yang memiliki skor paling kecil dibanding simpul lainnya. Best first search menjadi jalan alternatif untuk menggabungkan manfaat dari metode depth dan breadth first search.
Sebagian penulis menggunakan alogritma best first search untuk merujuk pada pencarian heuristik. Heuristik sendiri merupakan metode yang lebih fokus dalam pengembangan efisiensi dalam pencarian dibanding kelengkapan. Para penulis yang menggunakan best first search biasanya mencoba memperkirakan jarak pada ujung jalur dengan solusi. Jika ada jalur yang lebih dekat dengan solusi, maka jalur itu akan diperpanjang terlebih dahulu . Jenis pencarian khusus ini disebut greedy best first search atau pure heuristic search. Greedy best first, dalam notasi matematika ditulis f(n) = h(n), karena hanya memperhitungkan skor perkiraan saja. Adapun skor yang sebenarnya tidak diperhitungkan.
Menggunakan algoritma greedy best first akan memperluas suksesor pertama dari parent. Jika suksesor telah terbentuk, akan ada dua kemungkinan. Yang pertama, jika suksesor heuristik lebih baik dari pada parent nya, maka suksesor akan diatur di depan queue (parent dimasukkan kembali di belakangnya), dan pengulangan kembali dimulai. Kemungkinan kedua, suksesor akan dimasukkan ke dalam queue (ke lokasi yang ditentukan oleh nilai heuristiknya). Prosedur akan mengevaluasi suksesor yang tersisa dari parent.
Selain greedy best first, algoritma pencarian A* merupakan contoh lain dari algoritma best first search. Algoritma A* menggabungkan uniform cost search dengan greedy best first search. Algoritma ini disebut complete dan optimal karena skor yang diperhitungkan didapat dari skor sebenarnya ditambah skor perkiraan, atau dapat ditulis f(n)= g(n) + h(n)
Selain greedy best first, algoritma pencarian A* merupakan contoh lain dari algoritma best first search. Algoritma A* menggabungkan uniform cost search dengan greedy best first search. Algoritma ini disebut complete dan optimal karena skor yang diperhitungkan didapat dari skor sebenarnya ditambah skor perkiraan, atau dapat ditulis f(n)= g(n) + h(n)
Fungsi heuristik: f(n) = h(n)
Dimana h(n) adalah estimasi jarak garis lurus dari node ke goal.
Untuk mengimplementasikan prosedur pencarian grafik, kita akan membutuhkan 2 dua daftar simpul. Yang pertama adalah OPEN, simpul yang sudah dibuat tapi belum dievaluasi, dan CLOSED, simpul yang sudah dibuat dan sudah dievaluasi.
Algoritma best-first search
Pertama kali, dibangkitkan node A. Kemudian semua suksesor A dibangkitan, dan dicari harga paling minimal. Pada langkah 2, node D terpilih karena harganya paling rendah, yakni 1. Langkah 3, semua suksesor D dibangkitkan, kemudian harganya akan dibandingkan dengan harga node B dan C. Ternyata harga node B paling kecil dibandingkan harga node C, E, dan F. Sehingga B terpilih dan selanjutnya akan dibangkitkan semua suksesor B. Demikian seterusnya sampai ditemukan node tujuan. Ilustrasi algoritma best-first search dapat dilihat pada gambar 3.4 dibawah ini.

Untuk mengimplementasikan algoritma pencarian ini, diperlukan dua buah senarai, yaitu: OPEN untuk mengelola node-node yang pernah dibangkitkan tetapi belum dievaluasi dan CLOSE untuk mengelola node-node yang pernah dibangkitkan dan sudah dievaluasi. Algoritma selengkapnya adalah sebagai berikut.
1. OPEN berisi initial state dan CLOSED masih kosong.
2. Ulangi sampai goal ditemukan atau sampai tidak ada di dalam OPEN.
a. Ambil simpul terbaik yang ada di OPEN.
b. Jika simpul tersebut sama dengan goal, maka sukses
c. Jika tidak, masukkan simpul tersebut ke dalam CLOSED
d. Bangkitkan semua aksesor dari simpul tersebut
e. Untuk setiap suksesor kerjakan:
a. Ambil simpul terbaik yang ada di OPEN.
b. Jika simpul tersebut sama dengan goal, maka sukses
c. Jika tidak, masukkan simpul tersebut ke dalam CLOSED
d. Bangkitkan semua aksesor dari simpul tersebut
e. Untuk setiap suksesor kerjakan:
i. Jika suksesor tersebut belum pernah dibangkitkan, evaluasi suksesor tersebut, tambahkan ke OPEN, dan catat parent.
ii. Jika suksesor tersebut sudah pernah dibangkitkan, ubah parent-nyajika jalur melalui parent ini lebih baik daripada jalur melalui parent yang sebelumnya. Selanjutnya perbarui biaya untuk suksesor tersebut dn nodes lain yang berada di level bawahnya.
Algoritma yang menggunakan metode best-first search, yaitu:
a. Greedy Best-First
Greedy Best-First adalah algoritma best-first yang paling sederhana dengan hanya memperhitungkan biaya perkiraan (estimated cost) saja, yakni f(n) = h(n). Biaya yang sebenarnya (actual cost) tidak diperhitungkan. Dengan hanya memperhitungkan biaya perkiraan yang belum tentu kebenarannya, maka algoritma ini menjadi tidak optimal.
Contoh Kasus
Permasalahan mencari jarak terdekat antara kota Arad dengan Bucharest menggunakan metode Best First search.

Solusi
Best First search merupakan metode yang menggunakan nilai heuristic, pada permasalahan ini heuristik yang digunakan adalah jarak kota-kota terhadap kota Bucharest jika ditarik garis lurus yang jaraknya seperti yang tertera di atas dengan asumsi kota terhubung yang letaknya paling dekat dengan kota Bucharest adalah jalan yang paling optimal.
Diagram pohon langkah-langkah penelusuran dengan metode Best First Search adalah sebagai berikut :







pada permasalahan diatas telah ditentukan jarak antara node. maka pada ucs akan membuka node yang memiliki nilai/cost antar node yang terendah.
pada gambar diatas jika kita buka
c = 10
b = 20
a = 10
karena nilai c dan a sama maka teserah mau buka yang mana lebih dahulu.
seandainya kita mebuka c maka kita teruskan pencariannya, jika kita buka
d = 10+5 =15
e = 10+40 = 50 (mencapai goal, namun nilai cost nya dirasa masih terlalu besar)
maka kita buka node d, lalu akan didapat
e = 10+5+30 = 45 (nilai pada pencarian ini pun terasa masih terlau besar) maka dari itu kita buka node yang kecil di awal tadi yaitu node a
setelah kita buka node a akan di dapat
e = 10 + 20 = 30 (di dapatkan goal dengan solusi terbaik)
dari kasus diatas dapat kita lihat, ada banyak cara unuk mendapatkan solusi. namun dari berbagai macam penyelesaian kasus, kita dapat mencari solusi yang paling optimal dan ini lah ke unggulan dari UCS.
Contoh Kasus
Permasalahan mencari jarak terdekat antara kota Arad dengan Bucharest menggunakan metode Best First search.

Solusi
Best First search merupakan metode yang menggunakan nilai heuristic, pada permasalahan ini heuristik yang digunakan adalah jarak kota-kota terhadap kota Bucharest jika ditarik garis lurus yang jaraknya seperti yang tertera di atas dengan asumsi kota terhubung yang letaknya paling dekat dengan kota Bucharest adalah jalan yang paling optimal.
Diagram pohon langkah-langkah penelusuran dengan metode Best First Search adalah sebagai berikut :


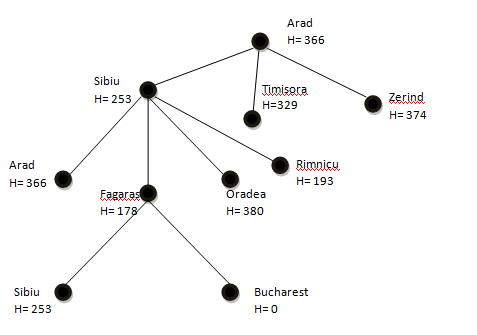
Dari Langkah-langkah di atas, didapatkan kota-kota yang harus dilalui untuk mendapatkan jalan yang paling dekat jaraknya dari Arad ke Bucharest dengan metode Best First Search adalah : Arad – Sibiu – Fagaras – Bucharest. Dari peta di atas, panjang jalan yang dilalui adalah 140+99+211 = 450 km.
Uniform Cost Search
Searching secara umum dapat dibagi menjadi Uninformed Search dan Informed Search. Uninformed Search sering disebut sebagai Blind Search. Istilah ini menggambarkan bahwa teknik pencarian ini tidak memiliki informasi atau pengetahuan tambahan mengenai kondisi di luar dari yang telah disediakan oleh definisi masalah.
Uninformed Search terdiri dari beberapa algoritma, di antaranya adalah:
- Breadth-First Search (BFS)
- Uniform-Cost Search(UCS)
- Depth-First Search
- Depth-Limited Search
- Iterative Deepening
Pada artikel ini, akan dibahas mengenai Uniform-Cost Search (UCS).
Jika seluruh edges pada graph pencarian tidak memiliki cost / biaya yang sama, maka BFS dapat digeneralisasikan menjadi uniform cost search
Bila pada BFS, pencarian dilakukan dengan melakukan ekspansi node berdasarkan urutan kedalaman dari root, maka pada uniform cost search, ekspansi dilakukan berdasarkan cost / biaya dari root.
Pada setiap langkah, ekspansi berikutnya ditentukan berdasarkan cost terendah atau disebut sebagai fungsi g(n) dimana g(n) merupakan jumlah biaya edge dari root menuju node n. Node-node tsb disimpan menggunakan priority queue.
Algoritma UCS dapat dilihat pada gambar berikut:
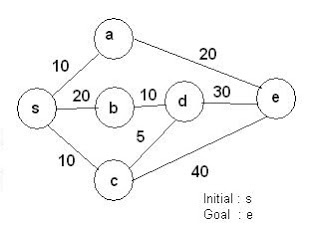
Perhatikan contoh pada gambar berikut ini. Nilai pada edge menandakan cost atau disebut juga g(n).
Penelusuran menggunakan UCS dari S ke G akan berjalan sebagai berikut.
- Frontier bernilai S
- Dari S, kita dapat menuju A, C, K dengan nilai 2,1,2. Untuk menyimpan pada frontier, perlu dilakukan sorting berdasarkan cost terendah. Sehingga dapat kita tuliskan f = C, A, K dengan cost 1,2,2
- Selanjutnya kita ekspansi C (yang paling rendah). Dari C kita bisa menuju D. cost dari C ke D adalah 1. namun, merujuk pada algoritma UCS, g(n) merupakan jumlah cost dari root menuju node n, maka g(n) untuk D dari C adalah 1 + cost sebelumnya menuju C yaitu 1 sehingga g(n) untuk D dari C adalah 2. Urutkan lagi berdasarkan cost.
Studi Kasus
Uniform Cost Search adalah sebuah algoritma pencarian untuk menemukan solusi yang optimal dan harga yang minimum.
Pada UCS, teknik pencariannya memperhatikan cost/jarak antara 1 node ke node lain.
Berikut ini adalah ilustrasinya :
Pada UCS, teknik pencariannya memperhatikan cost/jarak antara 1 node ke node lain.
Berikut ini adalah ilustrasinya :
 |
| Contoh Kasus Uniform Cost Search |
pada permasalahan diatas telah ditentukan jarak antara node. maka pada ucs akan membuka node yang memiliki nilai/cost antar node yang terendah.
pada gambar diatas jika kita buka
c = 10
b = 20
a = 10
karena nilai c dan a sama maka teserah mau buka yang mana lebih dahulu.
seandainya kita mebuka c maka kita teruskan pencariannya, jika kita buka
d = 10+5 =15
e = 10+40 = 50 (mencapai goal, namun nilai cost nya dirasa masih terlalu besar)
maka kita buka node d, lalu akan didapat
e = 10+5+30 = 45 (nilai pada pencarian ini pun terasa masih terlau besar) maka dari itu kita buka node yang kecil di awal tadi yaitu node a
setelah kita buka node a akan di dapat
e = 10 + 20 = 30 (di dapatkan goal dengan solusi terbaik)
dari kasus diatas dapat kita lihat, ada banyak cara unuk mendapatkan solusi. namun dari berbagai macam penyelesaian kasus, kita dapat mencari solusi yang paling optimal dan ini lah ke unggulan dari UCS.
Iterative Cost Search
IDS merupakan metode yg menggabungkan kelebihan BFS (complete dan optimal) dgn kelebihan DFS (Space complexity rendah atau membutuhkan sedikit memori). Konsekuensinya adalah time complexitynya menjadi tinggi.
IDS melakukan pencarian secara iteratif menggunakan penelusuran DFS dimulai dari batasan level 0. Jika belum ditemukan solusi, maka dilakukan iterasi ke-2 untuk level 1. Demikian seterusnya sampai ditemukan solusi. Untuk mempercepat proses, bisa menggunakan teknik parallel processing (menggunakan lebih dari satu processor).
Algoritma ini tidak memerlukan struktur data tambahan, melainkan menggunakan bentuk rekursif.
IDS melakukan pencarian secara iteratif menggunakan penelusuran DFS dimulai dari batasan level 0. Jika belum ditemukan solusi, maka dilakukan iterasi ke-2 untuk level 1. Demikian seterusnya sampai ditemukan solusi. Untuk mempercepat proses, bisa menggunakan teknik parallel processing (menggunakan lebih dari satu processor).
Algoritma ini tidak memerlukan struktur data tambahan, melainkan menggunakan bentuk rekursif.
 |
| Algoritma Iterative Cost Search |
Jika dilihat jumlah simpul yang dikunjungi setiap depthlimit :
Dephtlimit-1 : 1 + b
Depthlimit-2 : 1 + b + b2
Depthlimit = m : 1 + b + b2 + ... + bm
Maka, didapat kompleksitas waktu untuk algoritma ini yaitu :
max (O(m)+O(bm)+O(b2(m-1))+...+O((1)bm) = O(bm), bersifat eksponensial.
Depthlimit-2 : 1 + b + b2
Depthlimit = m : 1 + b + b2 + ... + bm
Maka, didapat kompleksitas waktu untuk algoritma ini yaitu :
max (O(m)+O(bm)+O(b2(m-1))+...+O((1)bm) = O(bm), bersifat eksponensial.

Comments
Post a Comment